Dense multilayer perceptron
This notebook illustrates the creation and the training of a densely connected multilayer perceptron.
[1]:
import os
import sys
sys.path.append(os.path.join(os.path.abspath(""), ".."))
import numpy as np
from IPython.display import Markdown as md
from torch import nn, optim
from nnbma.networks import DenselyConnected
from nnbma.dataset import RegressionDataset
from nnbma.learning import learning_procedure, LearningParameters
from functions import Fexample as F
Analytical function
In the following cell, we load and instantiate a vectorial function \(f\) implemented as a PyTorch Module. For more details on the implementation, see functions.py. You can implement your own by following the model.
The function is the following:
[2]:
f = F()
md(F.latex())
[2]:
Definition of the architecture
The densely connected multilayer perceptron is a novative architecture inspired by the convolutional architecture “DenseNet” mainly use for image recognition. This is a multilayer perceptron that concatenate at each layer every previous intermediate result. The fraction of new intermediate result created at each layer is called “growing factor”.
Below, an example from the related paper for 2 inputs, 10 outputs and 2 hidden layers of with a growing factor of 1:
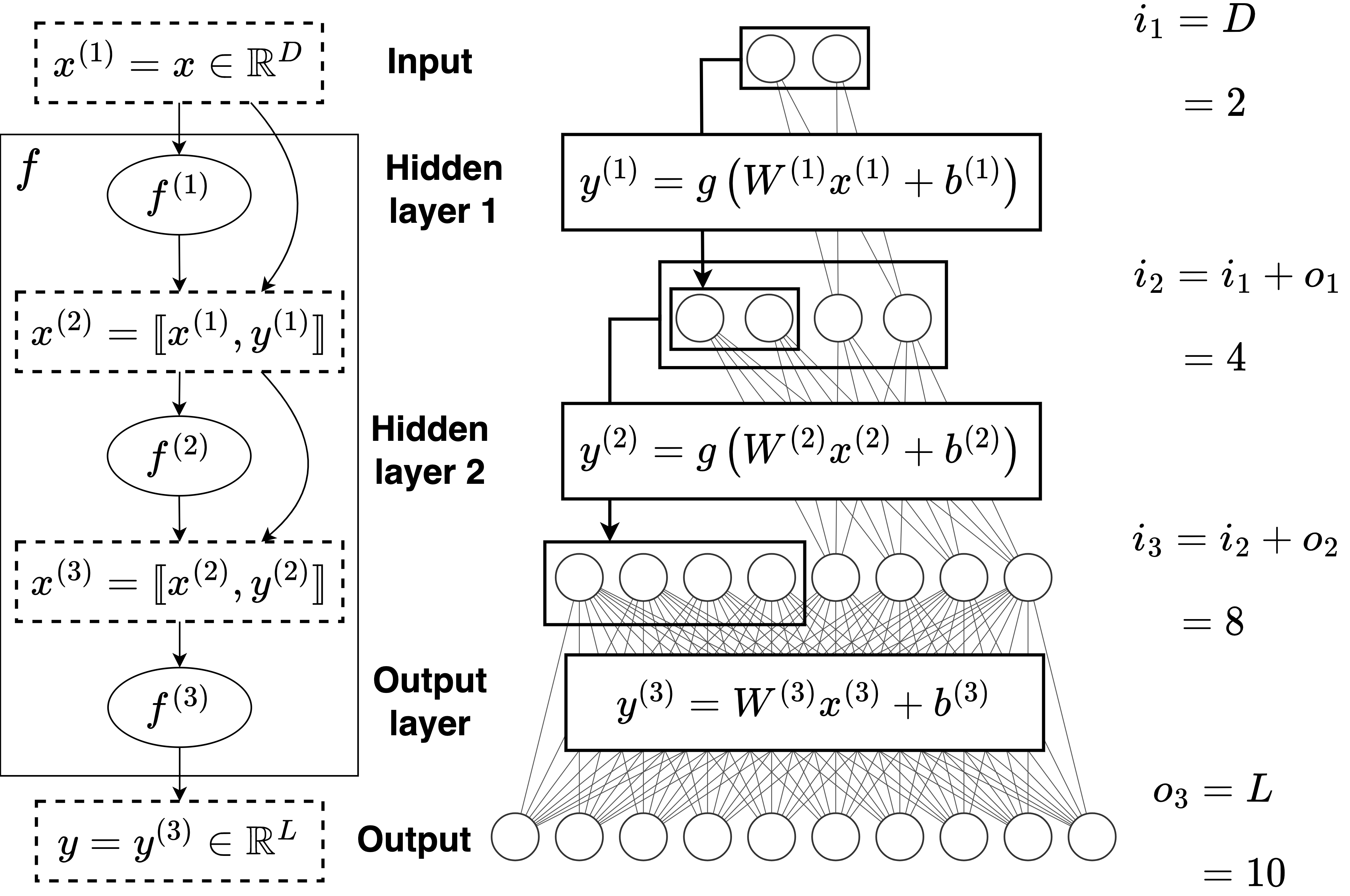
The interest of this architecture is that you can stack a lot of linear layers without experimenting issues such as vanishing gradient. Moreover, if some output features are proportional with some intermediate results, they will be propagated without forcing the network to approach the identity function.
The parameters that you can tuned in order to improve your model are the following:
the number of hidden layers
the growing factor (the lower is the growing factor, the higher the number of layer will be for the same number of parameter)
the activation function (for simplicity sake, in this implementation the same function is used for every layers)
the use of a batch normalization or not
You can also change the loss function that you use (see the section “Training procedure”).
With a DenselyConnected network, as well than for any network that inherits from NeuralNetwork, you can specify the input and output features names, the device (cpu or gpu, if available) that you want to use.
Lastly, you can also specifiy whether you want the last layer to be restrictable (see the restrictable-layer.ipynb notebook in this topic).
[3]:
n_layers = 10
growing_factor = 0.5
activation = nn.ELU()
net = DenselyConnected(f.n_inputs, f.n_outputs, n_layers, growing_factor, activation)
print(f"Number of hidden layers: {len(net.layers_sizes)-1}")
print(f"Layers sizes: {net.layers_sizes}")
print(
f"Number of trainable weights: {net.count_parameters():,} ({net.count_bytes(display=True)})"
)
Number of hidden layers: 10
Layers sizes: [2, 1, 2, 3, 4, 6, 9, 14, 21, 31, 3]
Number of trainable weights: 3,823 (15.29 kB)
Dataset
[4]:
n_samples = 10_000
test_frac = 0.20
np.random.seed(0)
X = np.random.normal(0, 1, size=(n_samples, F.n_inputs)).astype("float32")
Y = f(X)
X_train, X_test = X[round(test_frac * n_samples) :], X[: round(test_frac * n_samples)]
Y_train, Y_test = Y[round(test_frac * n_samples) :], Y[: round(test_frac * n_samples)]
train_dataset = RegressionDataset(X_train, Y_train)
test_dataset = RegressionDataset(X_test, Y_test)
print(f"Number of training entries: {X_train.shape[0]:,}")
print(f"Number of testing entries: {X_test.shape[0]:,}")
Number of training entries: 8,000
Number of testing entries: 2,000
Training procedure
[5]:
# Epochs
epochs = 100
# Batch size
batch_size = 100
# Loss function
loss = nn.MSELoss()
# Optimizer
learning_rate = 1e-3
optimizer = optim.Adam(net.parameters(), learning_rate)
[6]:
learning_params = LearningParameters(loss, epochs, batch_size, optimizer)
results = learning_procedure(
net,
(train_dataset, test_dataset),
learning_params,
val_frac=test_frac,
)
Results
[7]:
def metric(y_hat: np.ndarray, y: np.ndarray):
return np.mean((y_hat - y) ** 2)
[8]:
print(f"Loss over training set: {metric(net(X_train), Y_train):.2e}")
print(f"Loss over testing set: {metric(net(X_test), Y_test):.2e}")
Loss over training set: 3.82e-04
Loss over testing set: 1.81e-03